
皆さん、Google Colaboratory ご存知でしょうか?
主に機械学習で用いられ、ブラウザでPythonを記述することができる環境です。
機械学習を少し触ったことが人ならご存知かもしれませんが、以前までは、ローカル環境に Jupyter Notebook を立てる必要がありました。
それをそのままブラウザでできるようにしたのがGoogle Colaboratory (以下 Colaboratory)です。
1.Colaboratory の特徴
- 環境構築が不要
- Googleの他サービスと連携ができる
- 共有が容易
- 無料!
2.Colaboratory を始める
下記のURLからGoogleアカウントにログインすることですぐに始められます。(さすがGoogle…)
https://colab.research.google.com/?hl=ja
3.Kaggleタイタニックチュートリアルとは
機械学習を勉強する上でよく見かけるのがKaggleのタイタニックチュートリアルです。
簡単に説明すると、タイタニック号の生存者を予測するといったもので、乗客データのあらゆる特徴量から「生存したか・していないか」の2値分類をする問題です。
データ量が少ないのと、日本語での記事も多くあることから、機械学習にチャレンジしたい方におすすめのチュートリアルです。
4.実際にやってみる
今回詳しい概念やロジックの説明までは書かずにまずはやってみるという視点で紹介していきます。データ分析の流れは下記の通りです。
・タイタニックデータセット取得
TitanicDatasetはオープンデータとして公開されているので、下記のようにデータを取得できます。
from sklearn import datasets
X, y = datasets.fetch_openml(data_id=40945, return_X_y=True, as_frame=True)
コードを記入したら、左端(赤丸)の再生ボタンを押します。
するとコードが実行され、エラーが出ていなければ実行成功です。

Xには乗客のデータが入っています。Xと書き、実行することでデータを出力することができます。detasetsで取得したDataFlameはこのように自動的に見た目を整えてくれます。
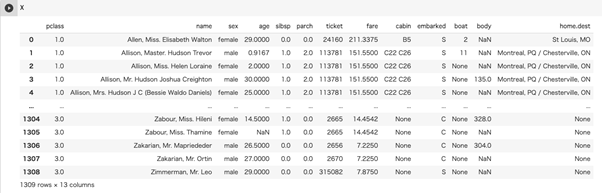
yには 0 (死亡) か 1 (生存) が入っています。 指標の計算をしやすくするために、型をint型にしておきます。
y = y.astype(int)
・データの前処理
ここから、機械学習にとって最も大事な作業と言っても過言ではないデータの前処理に移ります。
・欠損データの補填
まずは、データの欠損値を補填します(欠損値があるデータはゴミがたくさん混じっている状態なので)。欠損値がどこのデータでどれだけ発生しているかを確認します。
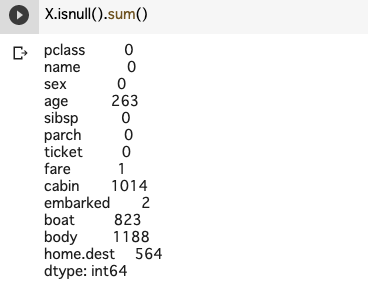
`age`は生存に関わりそうなデータなので、中央値で補填してあげましょう。`fere`は1つだけ欠損値があるので、一番多い`S`で補填してあげます。
X[“age”] = X[“age”].fillna(X[“age”].median())
X[“embarked”] = X[“embarked”].fillna(“S”)
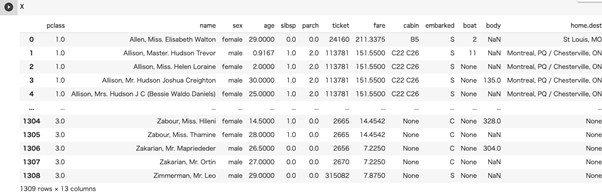
・文字列データの数値化
データを見てみると数値ではなく、maleやfemale、SやCなど文字列の値があります。文字列のデータは解析できないため、数値に変換します。
まず、データ解析を容易にすることができる、データ解析ライブラリPandasを読み込みます。
import pandas as pd
性別データは男女の二択なので、先頭のデータと同じかそうでないかで0, 1を入れます。
X[“sex”] = pd.get_dummies(X[“sex”], drop_first=True)
`embarked`はC,Q,Sの三択なので、それぞれを分解して、Cであるかそうでないか、Qであるかそうでないか、… の0, 1のフラグにします。
X = pd.concat([X, pd.get_dummies(X[“embarked”], prefix=”embarked”)], axis=1).drop(columns=[“embarked”])
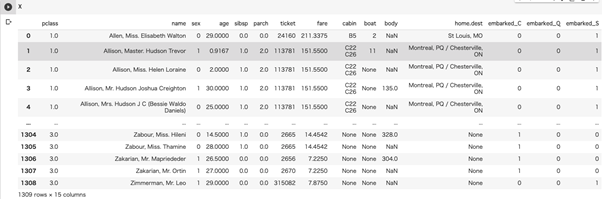
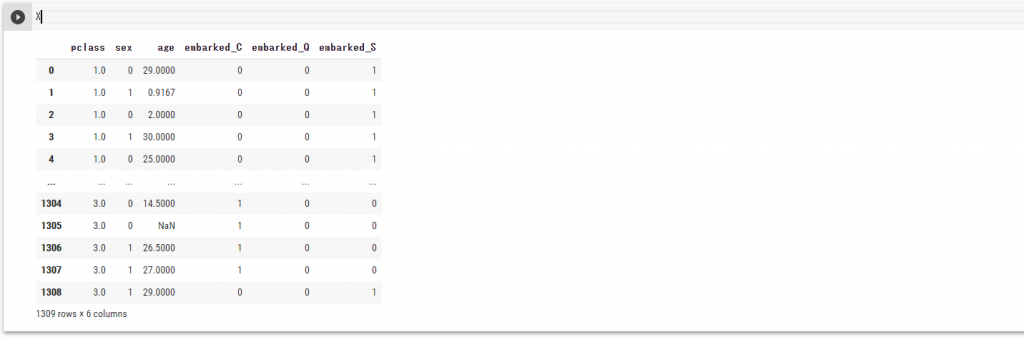
`sex`と`embarked`データを数値にすることができました。
また、今回使用しないデータはここで除外しておきます。
feature_columns =[“name”, “sibsp”, “parch”, “ticket”, “fare”, “cabin”, “boat”, “body”, “home.dest”]
X = X.drop(columns=feature_columns, axis=1)
使用しないデータが除外されました。
・トレーニングデータとテストデータに分ける
教師あり学習をするので、トレーニングデータ(学習用データ)とテストデータ(検証用データ)に分けます。
from sklearn.model_selection import train_test_split
seed=0
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=seed)
学習用データはモデルを学習させ、検証用データはモデルの精度を測るために使用します。
今回は全データの30%を検証用のデータとしました。
・モデルの学習
今回は2値分類ということで、決定木を使ってモデルを構築します。
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()
tree_model.fit(train_X, train_y)
・モデルの評価
検証用データを使ってモデルを評価してみます。
pred_X = tree_model.predict(test_X)
metrics.accuracy_score(test_y[“survived”], pred_X)
> 0.816793893129771
82%ぐらいの正答率ですね。
学習用のデータをもっと多くしたり、特徴量(列)を増やしたり、モデルを変えたりすることで正答率を向上させることができます。
5.おわりに
今回は Colaboratory の紹介と機械学習のチュートリアルを一通りやってみました!
事前の知識や理解をしないといけない部分はありますが、ざっくりと Colaboratory の使い方と機械学習ってどんなことをしているのかを知っていただければ幸いです。
【著者プロフィール】
バレットグループ株式会社
バレットグループは「人とテクノロジーで世界をつなぐ」を企業理念に掲げ、インターネットマーケティング事業、ECマーケティング事業、ICTソリューション事業を展開しています。
自社ブログでは、他にもインフラ系からデザイン系、業務改善、ポエムなどなど幅広く記事を公開しています。皆様のお役に立てることを願ってこれからも更新していくので、是非ご覧ください!
webサイト:バレットグループ
Blog:Colorful Bullet